Tuesday, March 16, 2010
The .Text blog engine my site runs on is getting pretty crusty. The project was absorbed into Community Server years ago and is no longer maintained.
I want to upgrade to a modern engine but I ran into a problem: there's no good way to import and export .Text blog content to a new engine.
I couldn't find an Atom or BlogML converter for .Text so I wrote my own.
Here's the binary. Pass in the connection string to your dottext database. If you have multiple blogs on one install it will export each in an individual file.
I'm also posting the code here. The few references to .Text converters I found online had broken links. If that happens when I eventually convert my site at least it should be possible to compile from whats left. The code is quick and dirty but it serves its limited purpose.
Once the data is BlogML format it should at least be workable to import it into other blog engines even if it needs a conversion to Atom or a proprietary format. I'm considering using something like http://atomsite.net/ but first things first, I've got to get all the data exported.
The .Text export code:
using System;
using System.Collections.Generic;
using BlogML;
using BlogML.Xml;
using System.Data.SqlClient;
using System.Data;
using System.IO;
using System.Linq;
using System.Linq.Expressions;
namespace dtBlogML
{
class Program
{
private static string ConnectionString;
static void Main(string[] args)
{
if (args.Length == 0)
{
Console.WriteLine(String.Format("{0}Exports dottext blogs to BlogML{0}Each blog is output in the current directory to a separate xml file." +
"{0}Connection string to the dottext database must be passed in." +
"{0}usage:{0}dtBlogML " +
"{0}ex: dtBlogML \"Data Source=0.0.0.0;Initial Catalog=dottext;Persist Security Info=True;User ID=user;Password=password\"", Environment.NewLine));
return;
}
ConnectionString = args[0];
//gather up the base blogs
DataSet dsBlogs = ExecuteDataset(ConnectionString, "select * from blog_config");
foreach (DataRow row in dsBlogs.Tables[0].Rows)
{
//each entry represents a different blog config complete with posts, comments, articles, etc..
BlogMLBlog blog = new BlogMLBlog();
blog.RootUrl = row["host"].ToString();
blog.Title = row["title"].ToString();
Console.WriteLine("Exporting " + blog.Title);
blog.SubTitle = row["subtitle"].ToString();
blog.Authors.Add( new BlogMLAuthor() { Email = row["email"].ToString(), ID = row["username"].ToString(), Title= row["author"].ToString() });
//grab the categories in one go and add them as need
//only interested in categories 1 and 2 in the dottext database
DataSet catDS = ExecuteDataset(ConnectionString,
"select * from blog_LinkCategories where blogid = @blogid and CategoryType in (1,2)",
new SqlParameter[] { new SqlParameter("@blogid", (int)row["blogid"]) });
foreach (DataRow catRow in catDS.Tables[0].Rows)
{
//init the category data and add to the top level blog entry
//posts will be marked with the category ref where needed
BlogMLCategory category = new BlogMLCategory()
{
Title = catRow["title"].ToString(),
ID = catRow["categoryid"].ToString(),
Description = catRow["description"].ToString()
};
blog.Categories.Add(category);
}
//load entries and articles
LoadEntries(blog, (int)row["blogid"]);
BlogMLSerializer.Serialize(new FileStream(Path.Combine(Environment.CurrentDirectory, "blogml-" + blog.Title + ".xml"), FileMode.Create), blog);
}
Console.WriteLine("done....");
Console.ReadLine();
}
private static void LoadEntries(BlogMLBlog blog, int blogid)
{
//can't just join the categories on the posts since its one to many and we'll dupe the posts
//quick and dirty: just load references in memory - shouldn't be too bad... i hope
DataSet catRefDS = ExecuteDataset(ConnectionString,
"select postid, categoryid from blog_Links where blogid = @blogid and postid > -1",
new SqlParameter[] { new SqlParameter("@blogid", blogid) });
//load the entries, articles, and comments
//to load everything in one go the index of posts/articles needs to be tracked
//the posts can't be pulled up later by id so do it manually
Dictionary table = new Dictionary();
SqlDataReader sdr = ExecuteDatareader(ConnectionString,
@"select * from blog_Content c left outer join blog_EntryViewCount evc on
evc.EntryID = c.ID
where c.BlogID = @blogid",
new SqlParameter[] {new SqlParameter("@BlogID", blogid)});
while (sdr.Read())
{
//post or article
if ((int)sdr["posttype"] == 1 || (int)sdr["posttype"] == 2)
{
//quick init what we can
BlogMLPost post = new BlogMLPost()
{
Title = (string)sdr["title"],
ID = sdr["ID"].ToString(),
DateCreated = sdr.GetDateTime(sdr.GetOrdinal("DateAdded")),
DateModified = sdr.GetDateTime(sdr.GetOrdinal("Dateupdated")),
PostUrl = sdr["entryname"].ToString() ?? sdr["id"].ToString(),
Views = 0,
HasExcerpt = (sdr["description"] == null),
Content = new BlogMLContent() { Text = sdr["text"].ToString() }
};
//.text is single author so just add it back in
post.Authors.Add(blog.Authors[0].ID);
//post or article?
post.PostType = (int)sdr["posttype"] == 1 ? BlogPostTypes.Normal : BlogPostTypes.Article;
//may end up being the final part of the url on import
if (!(sdr["entryname"] is DBNull) && sdr["entryname"].ToString() != "")
{
post.PostUrl = sdr["entryname"].ToString();
}
else
{
post.PostUrl = sdr["id"].ToString();
}
//any excerpt?
if (post.HasExcerpt)
{
post.Excerpt = new BlogMLContent() { Text = sdr["description"].ToString() };
}
//add the view count
if (!(sdr["WebCount"] is DBNull))
{
post.Views = Convert.ToUInt32(sdr["WebCount"]);
}
//find the post categories if any
var query = catRefDS.Tables[0].AsEnumerable()
.Where(pid => pid.Field("postid") == Convert.ToInt32(post.ID));
//add the categories to the post/article
//could have more than one
foreach (DataRow cat in query)
{
Console.WriteLine(cat["categoryid"]);
post.Categories.Add(cat["categoryid"].ToString());
}
//add post to the blog
blog.Posts.Add(post);
//add to lookup table for comment addition later on
table[post.ID] = post;
Console.WriteLine("...... exported " + post.Title);
}
//comments
if ((int)sdr["posttype"] == 3)
{
BlogMLComment cmnt = new BlogMLComment()
{
DateCreated = sdr.GetDateTime(sdr.GetOrdinal("dateadded")),
DateModified = sdr.GetDateTime(sdr.GetOrdinal("dateupdated")),
ID = sdr["id"].ToString(),
Title = sdr["title"].ToString(),
UserName = sdr["author"].ToString(),
UserEMail = sdr["email"].ToString(),
UserUrl = sdr["titleurl"].ToString(),
Content = new BlogMLContent() { Text = sdr["text"].ToString() }
};
//add to the post
table[sdr["parentid"].ToString()].Comments.Add(cmnt);
}
}
}
#region Util
public static DataSet ExecuteDataset(string connectionString, string queryString)
{
return ExecuteDataset(connectionString, queryString, new SqlParameter[] { });
}
public static DataSet ExecuteDataset(string connectionString, string queryString, SqlParameter[] parameters)
{
DataSet dataset = new DataSet();
using (SqlConnection connection = new SqlConnection(connectionString))
{
SqlDataAdapter adapter = new SqlDataAdapter();
adapter.SelectCommand = new SqlCommand(queryString, connection);
foreach (SqlParameter parameter in parameters)
{
adapter.SelectCommand.Parameters.Add(parameter);
}
adapter.Fill(dataset);
return dataset;
}
}
public static SqlDataReader ExecuteDatareader(string connectionString, string queryString)
{
return ExecuteDatareader(connectionString, queryString, new SqlParameter[] { });
}
public static SqlDataReader ExecuteDatareader(string connectionString, string queryString, SqlParameter[] parameters)
{
SqlConnection connection = new SqlConnection(connectionString);
connection.Open();
SqlCommand cmd = connection.CreateCommand();
cmd.CommandText = queryString;
foreach (SqlParameter parameter in parameters)
{
cmd.Parameters.Add(parameter);
}
return cmd.ExecuteReader(CommandBehavior.CloseConnection);
}
#endregion
}
}
Saturday, April 19, 2008
The toughest set of data to obtain for geocoding is a zip code to city translation.
Unfortunately, the USPS treats zip data as a trade secret and demands licensing fees for distribution which makes creating a free geocoder a little harder.
You used to be able to obtain a decent city to zip mapping from the FIPS55 data set. However, the FIPS folks were force to remove this information from all future releases. I still have the old FIPS data which I can use if worse comes to worse, but I'm trying to find a way around it by generating the data myself if at all possible. This way the data doesn't get continually out of date.
While going through the new census data format I thought I stumbled upon a way to extract city data.
First a little background on why this data is important, then I'll show you so pictures of why its so difficult.
For each street in the database we have the associated zip code. Actually we have two zip codes, one for each side of the street, but they are generally both the same. The zip code of the street is the main way in which we narrow down the search space for an address.
For example, if you tried to geocode “123 Main St Anytown, NY” the first step is to figure out what the possible zip codes are for Anytown, NY then see if we have any street names in that zip range. Note that if you try to geocode with just the zip code this is a non issue. “123 Main St 12345” could be geocoded without the city lookup at all. However, when we display information about the address it would be nice to know where that place is by using the zip to display the city.
The census data does contain names and geometry for most “places” (city, towns, etc.) so I investigated extracting the shape of all the cities in the country.
It also contains the shapes of what the census calls ZCTAs or “Zip Code Tabulation Areas.” I was hoping to overlay these two sets of data, then go through each place to extract every zip code it touches.
Unfortunately the “place” geometry doesn't give very good coverage as it uses very strict definitions for the boundaries of cities.
Here is a projection of the roads and a few landmarks in densely populated Fairfax County:
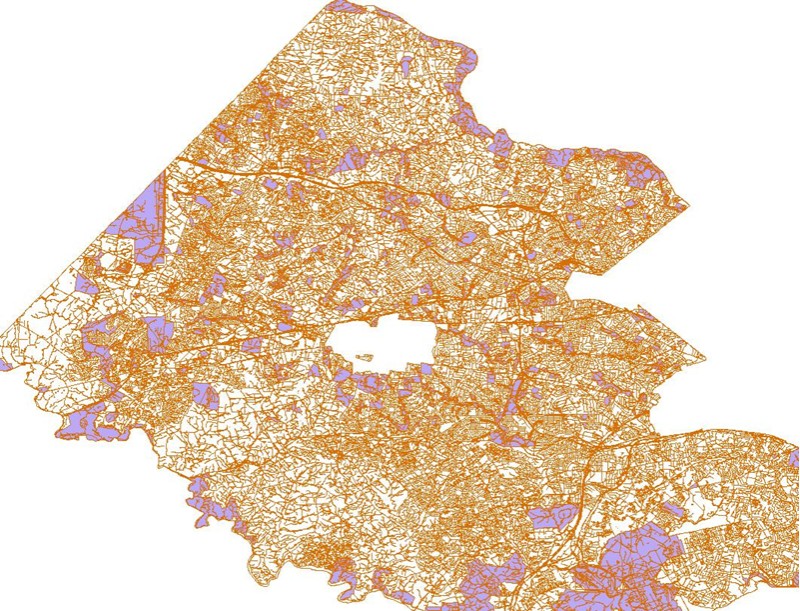
All of these roads are in a city of some sort as you or I would know them, but when you overlay the census city shape data (green) it looks like this: 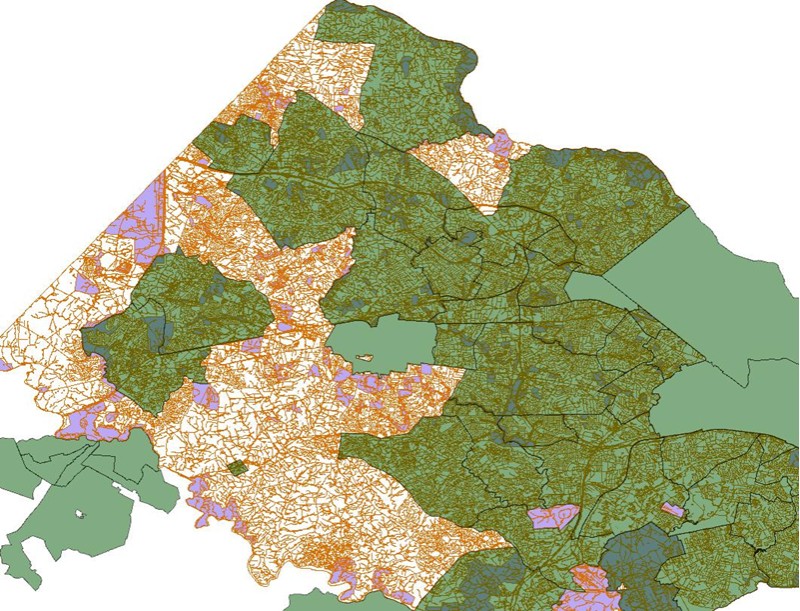
As you can see the place data doesn't even come close to covering all the places where people live.
There still may be a way to get the data out of here, but its going to be tougher than I had hoped.
In the meantime the database creation can continue, its just going to have a few place holders where the zip translation can be plugged in later.
Wednesday, April 16, 2008
After two kids and a long break I'm finally working on the new geocoder.
All the previous realeases have been rendered moot due to change in the way the census releases the data.
Frankly, this is one of the reasons I took such a long break from it since they announced several years ago this was going to happen.
As we speak I've completed about 75% of the work required to load the new data.
The good news: this one should be totally cross platform. The database creation is being done by a python and I'm testing it on both linux and windows.
Actual geocoding will be done by separate APIs for each language. Right now I've got C#, Java, and Python slated but it should be easy enough to reate more.
The bad news: I'd say any sort of stable release is a few weeks away. I really only get to work on it after the kids go to sleep.
The licensing will hopefully be way clearer this time. I'm kicking around GPLv3 with some sort of dual license for those who need more flexibility.
Stay tuned for more info!
Monday, May 15, 2006
Its back up. http://www.johnsample.com/reversegeo/
Here's what happened:
We were having quite a few people over Saturday for a party and when I went to make sure my MAME machine was still working I found out the motherboard was dead. I had a spare machine, but it was lacking a power supply since the week before I had given it to my brother.
Unfortunately it was 9 pm when I found out and all the computer stores were closed, so in a moment of mad scientist style hacking I wired the power supply of my main computer to the spare one without actually taking it out of the case. Picture jump starting a car, the cases were basically on top of each other with wires and drives snaked between them.
I was able to get the arcade computer to the point where all I would have to do is put in power the next day, however, somewhere in the process the chip fan power cable got knocked off of my main computer and the chip melted in the early morning.
That left me with 3 dead machines. Saturday morning before everyone came over I replaced the mobo+chip in my main computer and got power to the MAME machine, so all is well with the world at the moment.
Saturday, May 13, 2006
Through a freak accident I managed to fry 3 computers last night.
The demo db won't function and the downloads won't be available until I restore the boxes.
Tuesday, May 02, 2006
I've started working on the geocoding project again. There was some down time while we adjusted to having a newborn around and time was short.
FIPS has made some changes that will make distributing an installer virtually impossible. Mainly, the USPS had them remove zip code information from their publications. I've had to come up with another source of info at great expense, so I will probably only be able to distribute the db in pre built form unless another solution arises. This also means I'll need to start charging for it to make up some of the cost.
I know there were some people who had trouble downloading the zipped up db in the past. The problem is fixed now but the location has changed. If I sent you the download info and you were never able to retrieve it shoot me a line.
One of the coolest new features I'm working on at the moment is suggestions for misspelled streets and cities.
Wednesday, February 15, 2006
Getting subversion up and running for source control is proving more difficult than I thought when it comes to access control.
Everything is in VSS which would be perfect but running over the web isn't really possible.
In the meantime here is half of project. Two things are missing:
1. The database installer
2. The CrLab MySQL dll
3. AddressParse DLL source (Created in a separate program, I'll post details later.)
I'm waiting for a response from CrLab on whether I can include their dll. If I can't its an easy swtich back to the MySQL provided connector.
The installer is in no shape to be released at the moment so in the interim I'm going to give a download link through email. The compressed MySQL db is 2.5 gigs so you can understand why I can't post a link here. If you want a copy before the installer is up email me and I will give you a link if my bandwidth at home can take it.
The code is a maze of spaghetti in massive flux while moving to the spatial index, have some patience while reading it until everything is flushed out.
And without further ado:
http://www.johnsample.com/misc/geo3/geocode.zip
Friday, February 10, 2006
Ok, I've been talking about releasing the source for a while now so let me explain the delay and recruit suggestions on how to proceed.
First of all, thanks for the all the email. I stopped responding for a bit there and I hope to do better in the future.
Second, I'm torn on how to release the source. If you have seen the background of the project so far you'll discover this started as a pet project after I couldn't find any viable source for reverse geocoding information. The installer was a nice touch, but keeping up with both the evolving census data and actual improvements to the program has gotten out of hand. Right now the installer has been (obviously) rendered useless until I can revamp it.
Part of the lack of communication was due to an episode with a user who needed help. It was a long, drawn out, frustrating email exchange which eventually netted a working system. I later found out the user was the employee of a LARGE global consulting firm and they were putting it on a client's system. (Hehe, whoever the client is got ripped off.)
I love GPL zealots, but frankly I'm not one of them as my mortgage gets paid by designing software.
Before I release the source I'd like to find a way to license it so that it can be used by small developers/low commercial/nonprofit but also balance the need for compensation for commercial use. I'm not looking for the “give it away and make money in support” model here because I really don't have the time and it would probably violate my employment terms.
What I'm looking for:
1. Allow non commercial use.
2. No reselling, repackaging, commercial use without permission, although this doesn't necessarily mean any purchase is involved.
Ideally I'd like to form some sort of co-op where contributors could benefit from commercial use.
Anyway, any ideas on how to license this thing to protect the time investment it requires?
Sunday, January 29, 2006