So what have I been working on the last few weeks? Well, I think I've come up with a way to store just about ALL the geometry and places in the census information.
What kind of stuff?
With the new method you could query for a golf course, apartment building, airport, etc. and get the outline not just a single long/lat point.
You could query for a school and get the outline of the entire grounds plus the point on which the building lies.
You could search for a lake, river, or park and do the same.
This includes all the other record types I've been getting emails about also (2, 4, 5, and more).
Why is it taking so long?
There is just no way to fit the architecture I need to use into a cross platform API, at least part of it.
First a little background:
This project started out as just an academic exercise to see if I could reverse geocode a few locations, something I couldn't find with any free software out there. A side effect of that was building a geocoder that (although incomplete) was pretty functional.
One thing I have constantly struggled with is the speed of the reverse geocoding. The forward lookups are fast, but I have exhausted every trick I know of and can't get the speed of the reverse lookups to a level I consider acceptable. Right now I use B-Tree index intersections but its still not cutting it.
The new architecture will allow forward and reverse lookups to be fast, efficient, and complete, but with one major drawback:
I can't do it with SQL Server.... at least the reverse part of it.
This doesn't mean I'm going to stop supporting SQL Server for the forward geocoding, its just not going to be as powerful as the MySQL version.
Why?
SQL Server doesn't support R-Tree indexes or geometric columns. R-Trees are the only way to make the reverse lookup fast and store all the points of line or polygon. SQL Server just doesn't support them, which is sad because generally given the choice of MSSQL or Oracle on projects I usually go with MSSQL.
Here is an example of why I need to switch the way the geometry is stored. With the way the points are loaded now, the API is only aware of nodes, not the actual streets. Currently when the blue point is reverse geocoded in the following picture, the result will be Street B (which is obviously incorrect) since we can only determine the closest point.
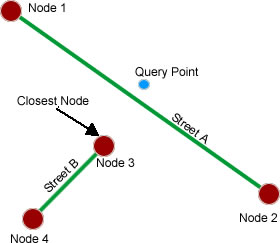
The new storage method will change this and the API will become aware of the actual lines in between nodes (as well as all the internal Type 2 nodes) and return the correct answer: Street A.
Where does this leave the MSSQL and Sqlite versions?
They will benefit from the merging of all the types so you will be able to query schools, malls, parks, plus all the extra streets but:
1. Only point locations will be stored, the polygon outline of the grounds and the Type 2 points will not.
2. Reverse geocoding will still return incorrect results in the above example.
Anyway, thats where I'm at. I'm putting together the load and merge scripts for the new architecture, but it will take a while longer to release them since I have to change the storage structure.